
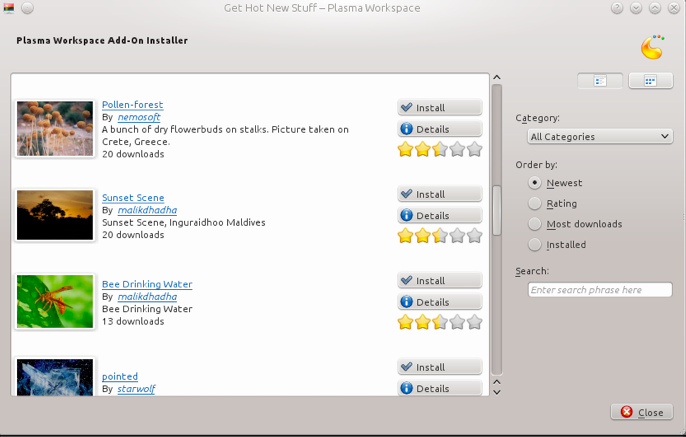
For up- and downloading documentation files in kdev-python, I wanted to implement support for the KDE GHNS dialog (you know, this thing). In addition to a good GUI dialog which makes it easy for people to generate raw versions of docfiles and edit them a bit, this could be quite effective in supporting binary python modules correctly in the IDE. Sounds easy enough to do, right? The widgets are there… so just use them. It’s not quite as easy tough…
Most applications which use the GHNS widget host their data on kde-*.org (e.g. kde-look.org for wallpapers). However, I didn’t want to do that, because
{kind=link}
- I don’t think this program’s data is particularily valuable to be browsable (is that even a word, browsable?) on a website like that — it’s not what people are looking for, it’s nothing you would see there and say “hey cool, I gotta download that and try it”
- The sites are not maintained by KDE, and are sort of closed — I can’t access the underlying data with a script easily, but I’d like to do that, in order to be able to e.g. ship some of it with my releases
- Other people have reported it to be a bit of an effort to get one’s own category on those sites
So, what to do? I have a virtual server at my disposal anyways, so i tought I would just go install an OCS server (OCS is name of the protocol being used by GHNS) there and be done. But, turns out — there isn’t any (reasonable, maintained) free implementation of the server side of this protocol.
Sigh. Alright, this can’t be so difficult, can it? So, I went ahead and created a very minimal implementation of the protocol in django + python, which only supports a small subset of the protocol. It implements exactly those methods which are needed to function with the KDE GHNS upload and download widgets (some fields are still missing, I’ll add them in the following days, also data validation and user registration are incomplete, but other than that it works). And let me tell you… this OCS specification!
The joys of the OCS specification
In general having a specification for uploading and downloading user-shareable content is a fine thing. But… this! Just look at the arguments you provide to create a new content entry. If you don’t want to open the link, it allows you to specify up to 12 download entities (why 12? I have no idea), with fields like “downloadbuyprice11” and “downloadpackagerepository9”. It also allows up to 10 (why 10?) homepage links to be specified (“homepagetype4”). Needless to say, if you request the data to be displayed in return, you’ll get (or, in my case rather, have to generate) XML like this (actual quote from the spec!):
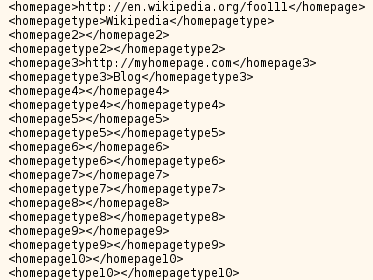 |
| XML, OCS style — sorry for using an image, but posting stuff containing tags in blogger is sort of impossible |
You might say, okay, yeah, it’s not great but it was probably the easiest way to get stuff done. I agree, especially since I’m also that kind of person which at some point will say “alright, f** elegance, let’s just get stuff done”. But, there’s a list of other things which are somewhat off in this specification, which just fit this kind of XML rather well:
- Every response contains a “status” field (which contains “ok” or “failed”) and a “statuscode” field. The status code is always 100 if the requests succeeds, and if it’s not 100 something went wrong. So, where’s the point of the status field?
- The specification mainly works through providing examples. That’s not a bad thing by itself, but it would be good if at least the field names and their possible values were always fully listed and explained outside of an example. This is not the case (example; example2 — here, what is e.g. “latitude”? How am I supposed to format the data in that field? I mean you can guess from the values in the example for a similar call, but still… Also note how a person only has 6 homepages while a content has 10… and 12 downloads… and 3 previews). Generally, there’s lots of stuff which is just unspecified and you can only guess it from the examples. Bad.
- Funny URL schemes: my favourite is “uploaddownload”
- In uploadfile, there’s various error conditions, but none matches e.g. “the item to which the file should be added was not found”. In return, there’s “localfile not found” which means… um… whatever… maybe the server couldn’t find the file on the client’s computer?
- It has typos. E.g. in edit, it has a field named “downloadtyp1”. This looks just weird, shouldn’t it be “downloadtype1″? What do I do now, implement the weird one and rely on everyone else following the spec closely too? Or guess that this is a typo and that everyone else probably corrected it? I’ll go for the former.
- It has nonsensical field values, e.g. this: donation – do you want donation for this entry? possible values are “yes” or “” for no donation. Sure, why allow “no” if you can just leave the field empty… I mean, specifying to treat empty as “no” is ok but this is just weird.
- In download, there’s this confusing thing: contentid – Id of a content; itemid – Id of a content — Hm. You can guess that the itemid probably means like “the 3rd download item in this content entry”, but what is it? Can I use my own IDs here? Probably not. Do they start at 0, or 1? Probably 1, but I don’t know.
- It leaves quite a few other questions open, for example, can there be more than one entry with a given title?
I could continue this list for a while, and I only tried to implement about a tenth of the spec.
Alright, I’ll stop whining now, I think my solution is roughly working now and I’ll just hope the specification will improve by a lot until I have to deal with it again in the future 😉
So now what? Well, I don’t know. It would in any case be a good idea to clarify this specification a bit to make it clear how it works exactly. Then, for what KDE uses it for it’s way too much stuff, one could go with a far easier specification (I think the following methods would be enough: list content, upload file, add entry, edit entry, check user, new user, download content). Thus, another option would be to dump the specification altogether and create a new, slim one. Or, just go live with it. 😉
Stay tuned, I’ll surely post about GHNS integration into kdev-python soon-ish.
Categories: Everything
Tags: ghns, kdev-python, planetkde
To be honest, it's a shame that KDE keeps on relying on some extremely closed platform that is "open" desktop (where's the open?). I hope that sooner or later (more later than sooner) a Free alternative is made.
I'd recommend to get together with Aaron. It might be the time to add support for a different protocol in GHNS and supports the free (and hosted on git.kde.org) bodega server.
This is now the third time that I hear these problems about OCS and not only from KDE developers I have heard that.
As Frank wrote, actually there were a few implementations already 1-2 years ago when I checked.
Too bad, no one stood up earlier, but even KDE got at least one for Gluon last year.
Hi Sven,
thanks a lot for you blog post. First I want to say thank you for writing a new OCS server. OCS was always as a distributed service but somehow one cared about writing and running new instances. So thanks a lot for that.
I agree with most of your critic about OCS 1.x It's written some time ago and a few people are working on version 2.x at the moment which should fix most of the things you mentioned.
So I suggest to get in contact with the other OCS people on the mailinglist if you want to contribute.
By the way: There are several free OCS servers already as listed on the website. 🙂
Frank
Hi Frank,
thanks for your reply. I'm glad to hear that OCS 2.x is being worked on, and that it aims to resolve the issues which 1.x has — that's a good thing in any case.
In terms of OCS serves, I have looked around a bit, and I have also asked #kde-devel — I did find a few implementations, but each had reasons why it didn't work for my use case (they were either old, or unmaintained, or both, or just didn't support the services which are necessary to use them with the KDE dialogs). I do know about your reference implementation which looks quite complete, but I only found it after I had started this already 😉
Cheers,
Sven
I am personally happy about your work. 🙂
Sven, I think we began the work on v2 in 2011: http://dot.kde.org/2011/05/18/open-collaboration-services-next-sprint
You can find the discussions on the mailing list. If I recall correctly, there was also a draft up on freedesktop.org for v2.
For a simple push-only OCS server:
git clone kde:synchrotron
In instance is already available on the KDE infrastructure. It does not support random uploads (it tracks git repos instead), but that could be added.
As for something newer / more modern than OCS:
git clone kde:bodega-server
There's already one instance hosted online, there's a C++ library and a Plasma Active client in the client repo:
git clone kde:bodega-client
The muon suite also has support for it now. There's the start to a web client:
git clone kde:bodega-webapp-client
Still things to do in Bodega, but it works and has a free software implementation.
Hi Aaron,
thanks for your reply. I had looked and tried both bodega-server and synchrotron, and somehow had to leave both again…
bodega seems like a good thing for the future, but given that it's designed for a quite different use case than mine (I need a desktop client) and that it's quite young, and written in a technology I have no idea about (this server-side JS thingy) I concluded that it would probably be more effort to get this running well than I was willing to spend on it right now. I'm sorry for this.
synchrotron looked like exactly what I was looking for, but somehow it doesn't support the methods the KDE GHNS widget needs? I tried it, and the widget seemed to call e.g. /content/categories and then failed, since the server didn't support that call. Also the server required some parameters for the other calls (e.g. provider=) which are not specified in the OCS protocol and which the KDE widget doesn't supply as far as I could see. In addition, it didn't support any kind of uploads. This again led me to the assumption that it would probably be more work to get this working for my specific use case than starting from scratch.
Greetings,
Sven
This kind of XML drives me nuts. One of the advantages of using XML is that you don't need to write your own parser, and it's easy to validate the document by providing a schema or DTD to the off-the-shelf parser you are using.
The "XML" example you quoted prevents that. It was written by someone who thinks XML is just words with angle brackets around them. And you need to do a lot of manual work and custom code to parse it, which is exactly what XML was supposed to avoid in the first place!
I had to deal with a server using "XML" like this in the past, and it just caused unnecessary work and frustration.
We have also made a JSON part for the standard that is now available in here: http://quickgit.kde.org/?p=scratch%2Flpapp%2Focs.git
The student was also doing a great job with implementing that JSON protocol in attica.
It could be even better with the OCS2 improvements.