
I recently rewrote most of kdev-python’s code completion code, as it was a huge mess (it relied largely on regular expression matching, which just isn’t powerful enough to do this properly). The result is less buggy, easier to maintain, and has unit tests (yay!). In the process, I also implemented quite a few features which I want to post a few screenshots of.
There’s a second issue I want to talk about in this post: A major problem which remains for kdev-python is the documentation data, that is, the way the program gets information about external libraries, for example functions and classes in those libraries. I’d love to have some help here — if you want to help improve kdev-python, this is a great point to start! There is no knowledge required about kdev-python’s code base, or even C++ (all that is to do here can be done in python). Read more below in case you’re interested.
Another note: kdev-python now has its own component on bugs.kde.org. Please report any issues you might encounter there!
Code completion features
Besides the increase in maintainability, a number of features have been added or improved in code completion.
Multi-level calltips
The primary reason for the rewrite was that I wanted to support multi-level function calltips, which just wasn’t easily possible with the old code. That feature works now:
 |
| Multi-level calltips |
As you can see, if the cursor is inside a function call which is passed as an argument to another function, you’ll get information about both functions (this works with an arbitrary depth, of course, not just with two functions). The parameter which you’re currently editing is highlighted in blue for both functions.
Named-parameter completion
Another improvement in function call completion is support for the “named parameters” feature: If you have a function which defines parameters with default values, you can specify their name followed by =, and then their value. This is now supported by kdev-python:
 |
|
| Named parameter autocompletion |
It’s even smart enough to not offer those items if you haven’t passed all non-default parameters already:
 |
| Named parameters are only suggested if all non-default ones have already been specified |
Note that all of the above screenshots use the “full completion” mode, which is only displayed if you explicitly request autocompletion with Ctrl+Space (by default). If you just type, minimal completion will be used instead, which is far less intrusive:
 |
|
| Minimal completion widget for named parameters |
The art of doing nothing
There’s many cases where an IDE just cannot offer useful (semantic) auto-completion, for example if you need to pick a name for a variable, class, or parameter. kdev-python now has more sensible rules for not offering semantic code-completion if it doesn’t make sense (the widget you see is the default kate text completion widget, which you could disable seperately, but which actually makes sense):
 |
| No semantic completion if you need to name a parameter |
 |
| No semantic completion if you need to name a variable |
Iterator completion
There’s now proper support for auto-completing a variable in a generator statement:
 |
| Generator variable auto-completion |
Notice the algorithm which guesses the variable you actually want to iterate over, which is not obvious just from the code the line contains.
Another new feature here is that if the last word is “in”, kdev-python will sort variables you can iterate over first in the list (note the green background colour):
 |
| Sorting variables by usefulness |
This is probably pretty useless, but it was easy to implement, so I did.
Import completion
This is not quite finished, it needs a bit of polishing (it currently completes stuff python does not allow, and does weird things like adding parentheses if you import a function), but it’s definitely better than it was before:
 |
| Code completion when importing single declarations from a module |
Shebang line completion
A ridiculously trivial but neverthereless useful feature is completion for the Coding and Shebang lines:
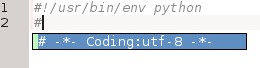 |
|
| Code completion for the “Coding” line |
Listing multiple encodings could be discussed, but doesn’t everyone use utf-8 anyways?
Call for help: Documentation data
Note: I will use the word “documentation” in the following sense here: it means not only the docstring or help text, but also basic information like “which classes are there in this library”, “which methods does this class have”, “which parameters does that function take”, and “which type of object does that function return” — in other words, all important information about a library’s public API. This information is necessary for various things, most importantly semantic highlighting and code completion.
Description of the problem
In C++, providing documentation for libraries (like Qt), is… well, not easy, but it’s at least obvious how to do it: You parse the header file the user code “#include”s, and that will tell you everything you need to know (well, given that your analysis code is intelligent enough to fully understand the file’s contents, which kdevelop’s C++ code is). In Python, the situation is much more difficult:
- The first type of problem are libraries which are written in python, but heavily rely on fancy python magic to set themselves up (for example, modify __builtins__, or iterate over lists of functions to do something with them); it will probably never be possible to determine the correct outcome of those setup scripts without actually executing them. Modules which currently suffer from this are, for example, os and parts of django (especially the ORM, but that will need some special-case handling in any case, which I have yet to think about) — kdev-python is not intelligent enough to understand what those do internally.
- Even worse are libraries which are written in pure C. By default, kdev-python cannot do anything about those.
Python has the “pydoc” tool, which can be used to obtain parts of the required information. However, pydoc will (partially) execute the code it analyzes, which is a no-go. If you wanted to use pydoc in an IDE, you’d have to heavily sandbox it, which I don’t want to do. Thus, I dismissed using pydoc, at least at run-time.
The current solution is simple: Files similar to the header files C/C++ has are shipped with kdev-python in case the information kdev-python can extract from the files that are shipped with the library is not sufficient. An example where this works really well can be seen in the QtGui / QtCore modules; the documentation for those is provided in kdev-python/documentation_files/PyQt4/QtGui.py. Victor Varvariuc wrote a script which generates those files from the Qt documentation a while ago, and it works great.
So, where’s the problem, then? The problem is, PyQt is well-documented in a systematic way, and other libraries aren’t. Look at the python standard library, for example: There’s no machine-readable documentation available which would even list classes and functions; function return types are, if at all, only documented in prosa text (yes, of course, strictly speaking, a function in python has no return type; but in most cases the type a function will return is actually fixed, and in those cases it would be useful to know it). The situation is similar for other important projects like numpy.
What needs to be done to improve the current situation
The following pieces of information are at least required in order to support a library in a remotely useful way:
- All classes and functions, and their members must be listed.
- For functions, at least the names of the parameters must be included, the types are nice but not so important.
- For functions a proper return type is very important (if you do i = button->icon(), and then want to access the properties of i, and icon() doesn’t have a return type, no completion or highlighting can be done — basically, even single functions with wrong return type can break highlighting and completion of large parts of a program’s code).
- Constants and their types must be listed.
That information then needs to be encoded in a python script (create empty functions / classes / etc. which just contain “return int()” or similar statements — see kdev-python/documentation_files for plenty of examples).
Some effort has been made in the past to support various libraries (for numpy there’s something that parses the online docs and converts that to such header files), but the overall situation is rather miserable. The worst thing is probably that not even the standard library is supported properly.
Conclusion
First of all, I don’t really know a good solution for this whole problem. If you have an idea, or know how other IDEs solve that problem, please tell me! I think eclipse uses pydoc or so and collects the information when you configure the interpreter, but the result is not good enough that I’d want to copy their behaviour.
There’s two important packages I have in mind for which the issue could probably be solved well in the “header files” way described above: the whole python standard library (os, sys, random, math, …), and numpy. If you’re interested in helping, please contact me, for example in IRC in #kdevelop on irc.freenode.net. Or just write an email.
Categories: Everything
Tags: codecompletion documentation, kdev-python, kdevelop, planetkde, python
I don't understand the problem, but python is a good language to use in Linux because there are a lot of people who use it, which translates into a lot of people to help. Just look at the dependencies in the deb packages from dotdeb.com. Almost all of them require python.
Good job!
Will this work in Kate? What do I have to compile to use this?
No, it won't work in kate. It's a plugin for KDevPlatform, which makes it usable in any application based on that (currently KDevelop and Quanta, where the latter is somewhat unmaintained). To use it, you'll have to compile kdevplatform, kdevelop, and kdev-python (all can be found on projects.kde.org).
Greetings
The inspect module (in the stdlib) has some bits that might help in that regard, in particular inspect.getmembers(), inspect.getargspec() and so on. There are also other bits like isclass(), ismodule(), isfunction() and so on.
Hm yes, I think that's what pydoc uses internally. But they often don't know enough, for example I remember they won't do much in case of C libs:
>>> import inspect, numpy
>>> inspect.getargspec(numpy.abs)
…
TypeError: is not a Python function
So that won't work, I think. 🙂
I wonder if the additions made by Sage would work?
http://www.sagemath.org/doc/reference/sagenb/misc/sageinspect.html
On second look, I don't think it would be easily decoupleable.
Hi,
PyCharm solves this problem really really well. It's worth a look. Since I'm a freelance Django developer, I've bought the license because it makes me much more productive.
PyCharm does a lot of symantic parsing / code analysis in the process. (don't know whether it's an embedded python interpreter, or code parsing). They also generate .py stub files for all .so files, including the __buildins__ and __future__ module.
Some of the things I've noticed:
– remember the return type.
– with 'assert isinstance()' the next code knows the type.
– with 'if isinstance()' the if-branch knows the type.
– detailed stuff like 'self.__class__.foo' also works.
– it understands kwargs.pop('name'), and gives the name= as parameter suggestion.
– it sometimes understands (*args, **kwargs), as it can look up where they are passed into.
– unknown symbols are highlighted with an offer to add the import (Alt+Enter). that is _really_ valuable.
– some detections are assisted with known defaults.
For example, it auto completes Django models. While you can define the 'objects' attribute on the class, it is added by Django using:
cls.add_to_class('objects', Manager())
A "Go to definition" on a default model actually takes me to that line. I guess they have implemented "add_to_class" as assignment function for a django Model class.
A similar thing can be one with true Django views. The first 'request' parameter is always an instance of a HttpRequest object. Since 'urls.py' lists all views, this can be implemented.
In fact, PyCharm allows a "go to definition" in the 'urls.py' or INSTALLED_APPS, or MIDDLEWARE_CLASSES, which all list the symbols as string.
Don't know if it's possible, but maybe you can even detect which variable types are passed to a function. That would allow type completion on parameters 😀
That said, I think you can achieve a lot already with static analysis, and further finetune it with some known defaults.
—
One other thing, I honestly really don't like that second "best matches" box. I actually find it really distracting with all it's matches based on inferred return types. I'd rather have a simple clean autosuggest like PyCharm offers, unless there is a very good reason this makes me more productive.
Typically you already know what variable or function you want to type there, don't you? Typing the first 2 letters is often enough to get the autosuggest anyway, so why bother with that large box in the first place? It takes takes an equal amount of keystrokes to get the suggestion.
I also wouldn't highlight functions as "function -> mixed foo(int arg)" because it isn't python syntax. Why not "def foo(arg: int) -> unknown" ?
Hope this helps, looking forward to good python auto complete in KDevelop! 🙂
Hello!
Thanks for your comment.
> They also generate .py stub files
> for all .so files, including the
> __buildins__ and __future__ module.
Do you have any idea how they do that?
> – remember the return type.
What do you mean by that?
> – with 'assert isinstance()' the next code knows the type.
> – with 'if isinstance()' the if-branch knows the type.
> – detailed stuff like 'self.__class__.foo' also works.
> – it understands kwargs.pop('name'), and gives
> the name= as parameter suggestion.
> – it sometimes understands (*args, **kwargs), as
> it can look up where they are passed into.
Those are easy to implement with what I have, but I didn't yet have the time to do it. 🙂
> – unknown symbols are highlighted with
> an offer to add the import (Alt+Enter).
> that is _really_ valuable.
Yes, that's planned already.
> For example, it auto completes Django models.
> While you can define the 'objects' attribute on
> the class, it is added by Django using:
I guess they have special support for Django, haven't they? This is on my todo list, too.
Do they have such python stub files for django, do you know?
> One other thing, I honestly really don't
> like that second "best matches" box. I
> actually find it really distracting with
> all it's matches based on inferred return types.
> I'd rather have a simple clean autosuggest like
> PyCharm offers, unless there is a very good reason
> this makes me more productive.
Set it to "always minimal completion" in the options, then. By default, while you're typing, only the minimal completion widget is shown. Did you try it out? I think it's fine as it is.
The "best matches" box is another thing… it's used to sort some items which are likely good matches at the top of the list, before all the alphabetically sorted items. What's the issue you have with that one? I don't quite understand the problem, I think.
> I also wouldn't highlight functions as
> "function -> mixed foo(int arg)" because
> it isn't python syntax. Why not "def foo(arg: int)
> -> unknown" ?
I find the "def" a bit out of place… but I'll consider changing that to something more reasonable, yeah.
Cheers
Hi, great to get your response!
> > They also generate .py stub files
> > for all .so files, including the
> > __buildins__ and __future__ module.
> Do you have any idea how they do that?
As far as I see, you can probe `__builtins__.__dict__` within the python interpreter. The __future__ module is just a .py file in the stdlib.
>> – remember the return type.
> What do you mean by that?
That PyCharm detects which return value a function has, and it remembers that, so for example:
def foo():
return SomeObject()
x = foo()
At this point, PyCharm knows that `x` is a SomeObject type.
> > (all other examples)
> Yes, that's planned already.
Awesome! 😀
> I guess they have special support for Django, haven't they?
Yes, that's something they also advertise with.
I don't think they have stubs, but rather have some hard-coded hints or assist the parser to recognize Django specific features, such as symbols in INSTALLED_APPS, urls.py and the `cls.add_to_class()` code. The last one is basically an "assignment operator", just written differently. Those features are understood at the lowest level possible, so it also works for your own classes.
I think in practice, you'll know where you'll miss auto completion, and start adding that. 🙂 Template tags come into my mind for example.
> The "best matches" box is another thing… it's used to
> sort some items which are likely good matches at the top of
> the list, before all the alphabetically sorted items.
> What's the issue you have with that one? I don't quite
> understand the problem, I think.
I kind of doubt it's usefulness, while it takes quite some space, distracting from the actual job. I'll see how it works out for me.
—
Thanks for considering my idea's, and I'll try the next version out! 🙂
Hello!
> As far as I see, you can probe
> `__builtins__.__dict__` within the python
> interpreter. The __future__ module is just
> a .py file in the stdlib.
Hm, okay, but that's not very powerful… no return types or similar 🙂
> def foo():
> return SomeObject()
>
> x = foo()
That has been supported forever in kdev-python.
> Don't know if it's possible, but maybe
> you can even detect which variable types
> are passed to a function. That would allow
> type completion on parameters 😀
This is implemented too. Just try it out. It's a somewhat complex feature, tough, and there's many reasons why it might not work in a particular case. 🙂
> …
Okay, if they have specialized django support, then it's easy to beat me. That's something I still need to start writing. It will be easy to do some special-case handling in the code for django… I'm just wondering whether there's a more generic approach (which would not make it necessary to modify the program code if you want to support further libraries with similar features).
> I kind of doubt it's usefulness, while it takes
> quite some space, distracting from the actual job.
> I'll see how it works out for me.
Yes, please keep me updated on that one. I didn't even consider that it might be seen as a bad thing by some people.
The main reason I introduced it was that I wanted to have matching locals sorted first, over the global variables. I find it far easier to hit the right item then, because it will *usually* be sorted first.
> Thanks for considering my idea's, and I'll try
> the next version out! 🙂
Sure, thanks for the feedback. The next version? You mean the first one 🙂
Hi, great work, it finally works!
Should I still be using the 1.3 branch with kdevplatform 1.3.x?
I don't think master works with 1.3.x, there has been a few changes since. Thus, you probably don't have much choice… but using master against 1.4 is far better for sure. 🙂