
I have implemented two new ways to filter the code completion popup in kate: filtering the list using an abbreviation, and filtering the list using text not occuring at the word’s beginning. This can probably best be demonstrated by lots of pictures:
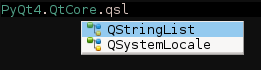 |
| You can match completion items by their abbreviation. This works for both camel case and underscore notation. |
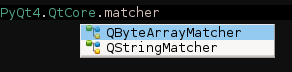 |
| You can also match entries by words they merely contain but do not start with. This matching is only allowed at word borders (capitals or underscores). This feature makes it far easier to find that damn class which has an unexpected name prefix, or the m_foo variable you thought was called foo. |
 |
| The abbreviation expansion engine also allows you to type parts of the words from the abbreviation, making your search more specific in a convenient way. |
This feature is not specific to kdev-python, it works in all kate-based apps. It is available in kate’s master branch, and will be available in KDE SC >= 4.12.
If you have more suggestions or cases which are not handled well, I’m happy to discuss this further. Have fun hacking!
P.S. If anyone can come up with an efficient algorithm for doing what is depicted in the last image, I’d be interested. The current one is quite slow for some corner cases.
- Extracting text from Photoshop (PSD) images
- kte-collaborative 0.2: First stable release of the collaborative text editing project
Categories: Everything
Tags: codecompletion, kate, kde, planetkde
Can you tell what the current approach is? Without much thought IMHO it looks like an advanced version of KMP could be applicable…
Currently, first all the word borders of the matched string (the one inthe completion list) are computed. Then, we walk through all the typed string (the one in the document), and compare them with the matched string: each letter must either match the next letter in the current word, or the first letter of the next word. If it matches both, the function will recursively call itself to decide with one should be used, i.e. it calls itself with the remaining pieces of both words to decide if there would be a match if the first letter of the next word was used, and if there's no match it will continue with the next letter of the current word. That's very slow if there's lots of equal letters, but I don't see a different way.
wow
QtCreator supports the same (when entering the letters directly in uppercase).
Maybe check what they doing.
Can you also write "QualIdent" there to match "QualifiedIdentifier"? Because that's what the problem is.
This is not really an elegant solution, but it's interesting to note, that you can reverse the search. So in the example you would start with "Matcher" and try to match (sorry, I could not resist) the longest possible string to the start of the word. So it would work like the following:
"t": does not equal "M"
"at" does not equal "Ma"
"mat" does equal "Mat"
"rmat" does not equal "Matc"
"rrmat" does not equal "Match"
stop, as "arrmat" would leave only two more characters, but there are three unmatched tokens left and each token needs at least one matching character.
⇒ The only possible combination is "mat".
So you could proceed from front to back and if there are multiple possibilities, you could switch processing from back to front hoping, that everything is unique this way. In general, I'd bounce on the remaining string and the remaining tokens and always take the way with less combinations and the trick outlined above to not try to find matches which will definitely lead to a dead end later on.
In case of multiple possible combinations I would also try to get through as fast as possible before trying other combinations, so in doubt match as much as possible (greedy) and first follow one token to the end instead of building up the whole tree of combinations. This should be faster because sometimes there might be multiple solutions and it does not matter which one matches, so it should be better to have a smaller subproblem left on average.
This might not really reduce the algorithms worst-case complexity, but it should improve the complexity of some cases.
Hmm, the issue I see here is that we also support partial matching, i.e. you could match QByteArrayMatcher also with "qbarr" or so… so you don't really know where to start on the end side. Or do you see a solution for that?
Plus I still think you can construct cases where the algorithm is very slow, no?
Maybe I should mention that this is not a problem in any real situation. The algorithm's complexity is theoretically horrible, but practically it's very fast for all kinds of *reasonable* input you can come up with (>2 million runs per second), and for sufficiently weird input there's a check which limits the runtime and just returns false. It also does some shotcut checks to dismiss mismatches quickly (which I'd guess catch > 99% of input strings, since almost all will usually mismatch).
I'm just annoyed by the fact that I couldn't come up with a more elegant solution.
Thanks for thinking about it, though, it's appreciated 😉
Maybe the following (via Planet Gnome) is a good approach:
http://browse.feedreader.com/c/Planet_GNOME/627062185
An interesting article, thanks!
However there are two reasons I think this is not useful in our case:
1) The author optimizes for the case of a large, static amount of text which will be searched frequently. Thus building an index makes sense of course, because you only need to do it once. In our case however, the text corpus is the completion list which changes every few characters typed; and the amount of searches conducted is very small because kate does partial matching, so in the usual case it's 1 search on the full list, and 1 search on 1/20 of the list, and the rest is negligible. Or something in that order of magnitude.
2) The author solves a slightly, but crucially different problem: "space" between characters is allowed in arbitrary places, whereas we only allow it when a new word (marked by a capital or an underscore) starts. If we omit this limitation, we also end up with a super-fast O(n) algorithm; the limitation is what makes it complex.
On this point we could of course discuss the usefulness of this restriction. Feel free to do so — I'm not totally sure it makes sense, it just sounds like it to avoid false-positives.
This is absolutely amazing! I've always been missing this feature in KDevelop and thanks to you it's everywhere, not just KDevelop.