
Last week I have been in Barcelona at the KDevelop / Kate sprint with all the other nice people working on those projects. As always, it was very cool to meet everyone again and spend a week together improving software. A big thanks to the organizers and sponsors, too!
Since most of the time I work on a fairly encapuslated subsystem (Python support for KDevelop) and only a smaller part of my contributions goes towards the KDevelop / Kate core repositories, I don’t have any world-changing news to announce — unlike for kate and KDevelop, no Qt5 / KF5 porting is happening yet in Python support. It doesn’t make much sense to start porting until all the interfaces have stabilized.
Still, quite some interesting things have piled up in the last few months, and especially during the sprint.
In the following, I want to give a quick summary of those.
News in KDevelop
Abbreviation matching in QuickOpen
Similar to the abbrevition matching feature introduced in code completion recently, this now also works
in KDevelop’s quickopen.
 |
|
| Abbreviations can now be used to filter the QickOpen and Outline lists. |
Improvements to the Execute Script plugin
Some issues were fixed in the Execute Script plugin, which is — among other things — used to run and debug Python files. Especially, clicking items now works properly when the output filter is being used; for common mimetypes, a suitable intepreter and output filter is pre-selected; and you can now run scripts directly from the context menu.
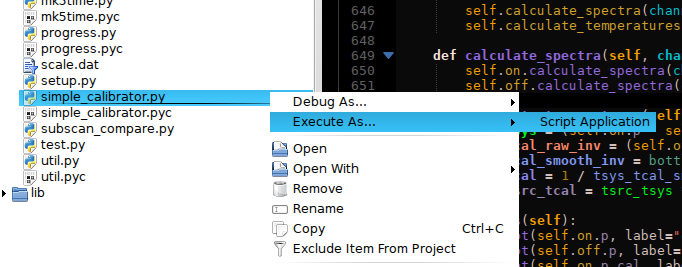 |
| Python scripts and other common scripts can be run without going through the Launch Configuration dialog. The interpreter is derived automatically from the mime type. If this automatic detection doesn’t work you can edit the resulting configuration in the Run | Configure Launches. |
You can now also create launch configurations which run or debug the script which is currently active in the editor.
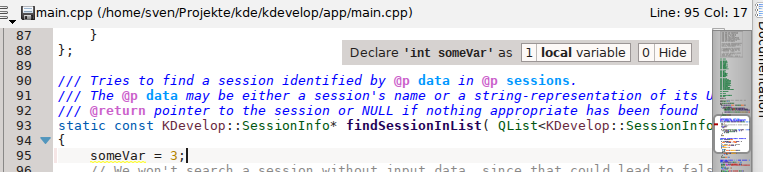
Revamp of KDevelop’s Problem Assistant
When you use KDevelop, you certainly noticed the small assistant at some point which pops up when there’s a problem in your code for which the language engine can propose corrections. This assistant was always very useful (not so much for Python yet, but I plan to implement some in near future) but had some problems in its current implementation. Especially, it looked really bad with the default colour schemes in some distributions; and its placement choice, which made it cover toolview controls quite frequently, was perceived as odd by many users I talked to. To make this assistant more flexible and more pretty, the widget was remade in QtQuick; it integrates with your editor colour scheme now and is placed inside the editor.
 |
|
| New assistant with default colour scheme for the editor |
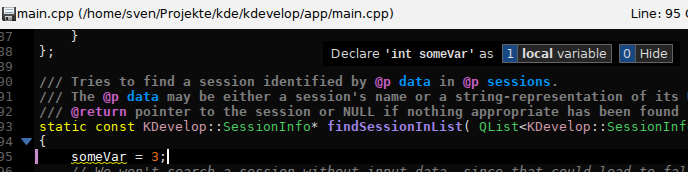 |
| New assistant with dark colour scheme for the editor. The blue highlight is added while you press the trigger key (default Alt, not currently configurable but could now be changed easily with the new implementation) |
There’s certainly room for improvement (comments welcome, just post them to the mailing list or the bugtracker), but the new implementation should make it easy to try different layouts and play with what works best.
Code completion item alignment
The Prefix (left column) of the completion widget is now aligned to the right, to avoid jumping of the text when scrolling through the list. This makes ist easier to find e.g. a function with a specific return type.
 |
| Types in the completion list are aligned to the right now. |
Annotations sidebar
An underrated feature is the git annotations sidebar. It has been even more useful since you can bind a shortcut to it (I suggest Meta+A), which makes it very easy to look at who wrote some code, or why, and at which time it was last changed (using a shortcut was possible since the last sprint actually thanks to Aleix whom I annoyed until he implemented it because I couldn’t figure out a proper way to do it). In this sprint, I fixed a few small issues with it; especially, it now uses proper colours when you have a dark editor background colour.
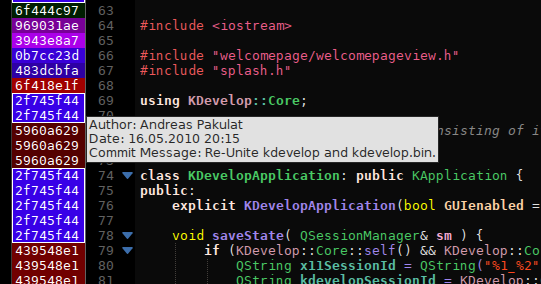 |
| The annotations sidebar now uses properly readable font colors on dark schemes. |
Automatic file reloading for git-managed projects
This feature has been there for a few weeks now but it turned out to be much more useful than I imagined (while other things I implemented turned out to be much less useful than I imagined — such is life). If you use KDevelop with git, you almost certainly were in the situation that you used e.g. git pull or git checkout while having affected files open in KDevelop, and then got lots of popup dialogs asking “The file was changed on disk, do you want to reload it?”. Those dialogs are by themselves a necessary and useful feature; they have protected me from data loss more than once, when I for example redirected the output of my program into its source file or fat-fingered some rm or git reset –hard command. For branch switches or similar operations, though, they are really annoying — and not only annoying, but dangerous too, since a warning with lots of false positives trains the user to click “ignore” as a reflex, and thus makes it possible that data loss occurs despite the warning. The aim of this feature is thus to attempt to reduce the dialogs to those situations where data loss could actually occur. The basic idea is, “when git has a version of a document in some tree, then the user can always go back there using git, so no data loss can occur”. So, when we know that a particular version of a document exists in some git commit, and that particular version of the document is currently open in the editor, and then the file gets changed on disk, it is safe to discard the open version and automatically load the new one.
This is implemented with a combination of git-hash-object and git-cat-file. When an open document changes on disk, KDevelop will take the text which is currently visible in the editor and pass it to git-hash-object. That command simply computes a checksum of the contents, which identifies the data. Then it passes this checksum to git-cat-file, which will tell KDevelop whether a file with this checksum exists somewhere in git’s object datbase. If that is the case, the document is reloaded (or closed, if it was deleted on disk) automatically, without asking the user if he wants to keep the old buffer; otherwise, the old behaviour (popup dialog) is applied. The rationale is that the user cannot lose data if the check succeeds, since he can always retrieve the old version from git’s object database (for most operations, simply using git checkout on the most recent entry in git reflog is enough).
The interface for implementing this for other VCS is there, but I doubt any of the current supported ones is flexible enough to support this.
News in kdev-python
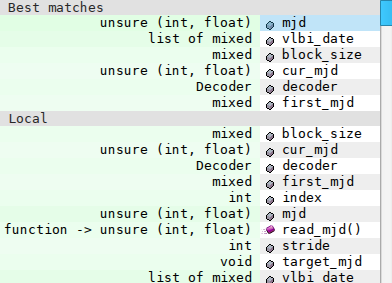
Item access on unsure types
In the python3 branch, we can now do this:
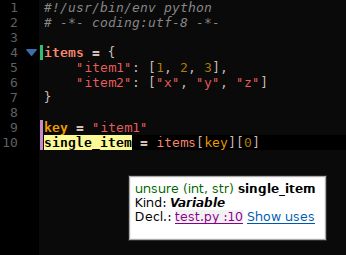 |
| Types are correctly deduced when a subscript is used on an unsure type. |
It’s a minor improvement, sure, but it didn’t work before and caused quite some code to not produce the correct types.
Calltips for constructors
Another very minor feature, but neverthereless annoying that it wasn’t there so far.
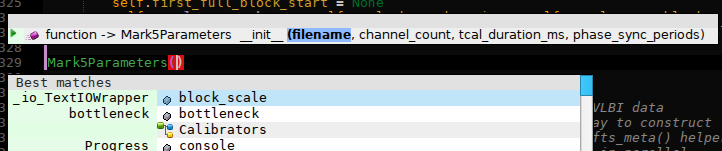 |
| Constructors now have call tips (the popup above the cursor) like all other functions. |
Less weird items in the import completion list
Items containing dashes are now filtered out of the import completion list. Ridiculous feature, I know, but useful neverthereless 😉
 |
| No more foo-bar.egg items in the completion list. |
Debugger
I don’t use the debugger much myself, so I didn’t notice it was quite broken since the 1.5 release (something about the output view changed in kdevplatform and I didn’t adjust the debugger code to work with it). Now it’s fixed, though, and I backported the fix to the 1.5 and 1.6 branches. Unfortunately, the debugger is still very hackish; as a user, you will most likely not notice that, but the code is a bit troubling 😉 It was originally only meant as a prototype, but worked so well that I didn’t yet implement it properly. If you have interest in improving the situation here — would be great!
Google Code-In: Specifying types
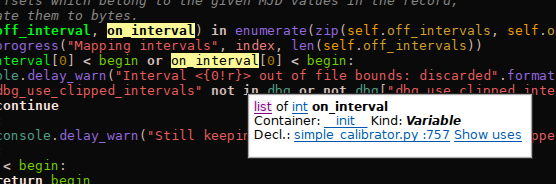
KDevelop’s python support also got some cool improvements from Google Code-In tasks this year, of which I want to outline the most noteworthy ones here. There has been a problem forever with libraries like matplotlib, which kdev-python can analyze quite well if you look at the internal code, but on which it still fails to provide proper completion and highlighting in many cases because some small, central piece of information is missing. That is hard to fix; the approach of shipping with a file containing all the function and class signatures from the library (which is e.g. used for PyQt) doesn’t scale well and is also very unelegant in this case because it is maintenance-heavy. What we can do now is this:
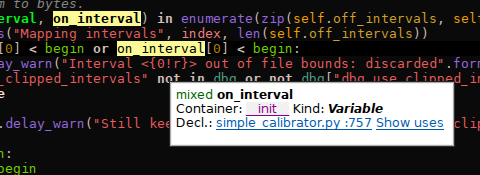 |
| Before: the type of the object is unknown. |
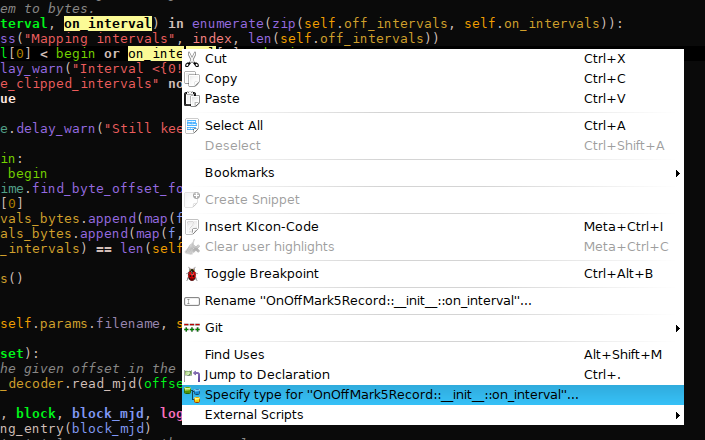 |
| Click “Specify type” in the context menu. |
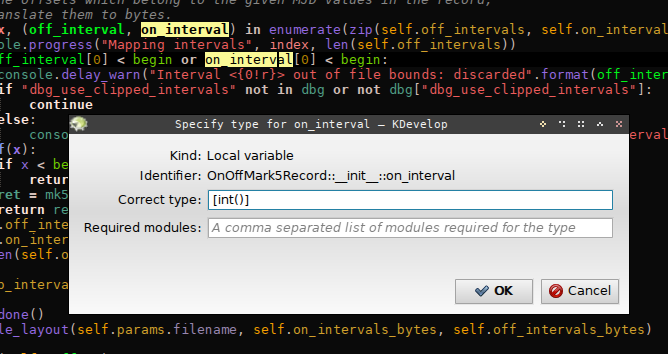 |
| A magic dialog opens. Enter a python expression which evaluates to the type you want the object to have; in this example, [int()] which evaluates to “list of int”. |
 |
| Confirm the dialog. Tada! |
The information on what object has what type is bound to the names of the objects and stored in small, python-syntax files (similar to the existing documentation files). Thus, for libraries like matplotlib, we can ship with a very small (20 lines-ish) set of hints which already greatly improve the quality of code completion and highlighting for that library. And the best thing is, thanks to the above assistant, it is very easy for users to do it themselves (there’s certainly room for improvement in the UI, e.g. imports should really be added automatically since they are hard to get right).
This is an experiment — we’ll see how well it works out in practice.
A prototype for this feature was implemented in a branch a while ago, and as part of Google Code-In, Atanas Gospodinov implemented the actual generation of the hint files from the informaton entered in the UI dialog (which is the key part of making it actually useful for end-users). In the sprint last week, I did some final fixes on it and merged the branch, and now it seems to be working quite nicely. One thing I want to emphasize when talking about this feature is that it is not meant to specify hundreds of types in your source code. If you do that, you will run into problems (consider using things like “assert isinstance(…)” instead — it makes your code nicer, anyways).
It is meant to make system libraries, especially those for which kdev-python understands almost everything but not a few key wrappers or similar, work better without having to modify those libraries themselves. In matplotlib, if you find the right place (the root cause of a problem in the analysis), often one hint is enough to fix e.g. dozens of function return types. If, for fixing your problem, you need to specify fifty function return types by hand, this is not the right feature to use.
Google Code-In: string formatting
Another Google Code-In task which deserves to be mentioned is the string formatting completion feature. It works like this:
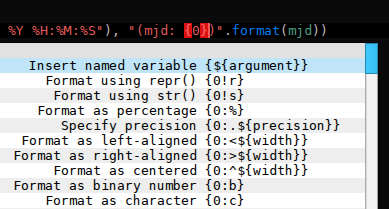 |
| The new string formatting completion, implemented by GCI student Atanas Gospodinov, allows to easily craft advanced expressions in python’s string formatting mini-language by repeatedly invoking code completion while the cursor is in a string literal. |
It was implemented by Atanas Gospodinov, too, and is quite nice when you (like me) can never remember the exact syntax for how to use this string formatting mini-language.
Unfortunately, this feature is one of the things which turned out to be less useful than I expected. That is not Atanas’ fault — his implementation is fine (it even uses kate’s awesome template engine!). It’s an inherent problem of the feature; you just don’t do the task it supports terribly often. For this reason, I disabled its automatic invocation (i.e. automatic popup while typing) in the current master branch; it will only show up when you request it manually using Ctrl+Space. Before doing that, I personally found it getting in my way too much when typing e.g. dict indexes which were strings. And not getting into your way is one of the key design principles of KDevelop.
Another GCI student which deserves to be mentioned is Levente Kurusa, who did some smaller fixes e.g. for binary operators.
Python 3
The Python 3 version is in the “python3-nofork” branch and can be compiled against Python 3.4 beta. It works quite nicely, and you could probably carefully start using it for actual work. It is even starting to gain some advantages over the Python 2 plugin, since I do no longer implement all new features in the Python 2 branch (in case ugly merge conflicts seem likely).
An official release will happen as soon as Python 3.4 gets released.
I have investigated making the Python 2 and Python 3 versions installable at the same time. Unfortunately, I currently don’t see a proper way to make this work. I’ll post an update in case I have an idea. Until that, the only way to get Python 2 and Python 3 support simultaneously (aka, in different KDevelop sessions which run at the same time — in the same session it’s not possible) is installing the two plugin versions into two different prefixes and creating helper scripts for launching KDevelop in those prefixes. I will publish a script which does this automatically in the future if I can’t find a better solution.
Debug vs. release mode
As a final word, I’d like to mention that it makes quite a difference in performance whether you compile kdev-python and kdevplatform in debug or release mode. For daily use of the program, I would really recommend building in release mode; everything is much smoother. If you encounter a crash, it has to be reproducable to be a useful bug report anyways, so you can just recompile in debug mode and trigger it again to get a proper backtrace.
Categories: Everything
Tags: codecompletion, kdev-python, kdevelop, planetkde, python
Awesome stuff!
Really brilliant progress!
The current kdev-python master would not compile against kdev-platform 1.6.0, right?
It might, I'm not sure. Chances aren't bad. You will have to change the X-KDevelop-Version in both the .desktop files in the repo fom 16 to 17 to make it load, though.
kdev-python is very nice work but I have trouble finding *any* documentation for its features. For example, I want to help semantic analysis locate python source files and expand the paths it searches. There is no information around!
You can ask on kdevelop@kde.org or in #kdevelop on irc.freenode.net.
kdev-python uses the include paths of your python interpreter, the current file's directory and all opened project's root directories as search paths. So you can either open your imported library as a project, or add it to $PYTHONPATH before starting kdevelop.